- 你的位置:世博官方体育app下载(官方)网站/网页版登录入口/手机版最新下载 > 资讯 > 世博体育AIME I是指2025年首场好意思国邀请数学测验-世博官方体育app下载(官方)网站/网页版登录入口/手机版最新下载
世博体育AIME I是指2025年首场好意思国邀请数学测验-世博官方体育app下载(官方)网站/网页版登录入口/手机版最新下载

裁剪:裁剪部 JHYZ世博体育
【新智元导读】就在刚刚,AIME 2025 I数学竞赛的大模子参赛成果出炉,o3-mini获取78%的最佳获利,DeepSeek R1拿到了65%,获取第四名。然则一位素质却发现,某些1.5B小模子竟也能拿到50%,莫非真的存在数据集浑浊?
大言语模子,到底是学会了处置数知识题,如故仅仅背下了谜底?
LLM的「Generalize VS Memorize」之争,迎来最新进展。
苏黎世联邦理工的筹划员Mislav Balunović,在X上公布了一众顶级AI推理模子在AIME 2025 I比赛中的成果。

其中,o3-mini (high)令东说念主印象额外深化,以额外低的资本处置了78%的问题。
DeepSeek-R1,则处置了65%的问题,况且它的蒸馏变体也弘扬可以,不愧是当先的开源模子!
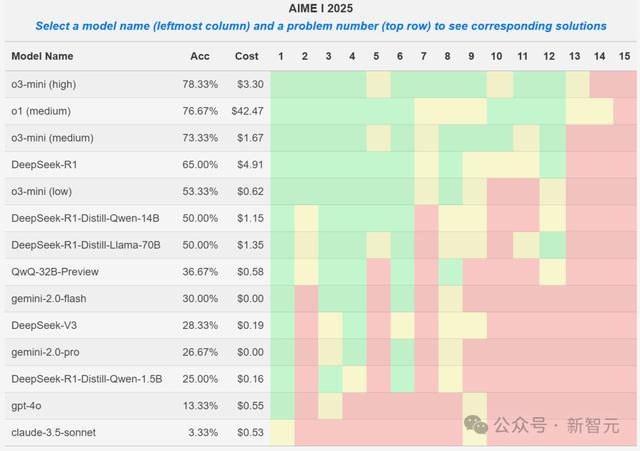
绿色暗示问题的解答率卓越75%,黄色暗示解答率在25%-75%之间,红色暗示解答率低于25%
然则,成真是的是这么吗?

AI作念出奥数题,只因原题已在网上流露?
威斯康星大学麦迪逊分校素质,现时在微软担任筹划员的Dimitris Papailiopoulos,对这一测试的成果提议了质疑。

素质暗示,我方对AI模子在数学题上获取的跨越,额外诧异。
原来他认为,一些较小的蒸馏模子遭逢这些题就寄了,没思到它们却拿到了25%到50%的分数。
这可太令东说念主惟恐了!
要知说念,如若这些题统统是新的,模子在西席经过中从未见过,按理说小模子能拿0分以上的分数就很好了。
一个1.5B参数的模子连三位数的相乘齐作念不出,成果却能作念出奥数题,这合理吗?
这就不由得让东说念主怀疑,其中有什么问题了。

AIME I是指2025年首场好意思国邀请数学测验,学生们需要在三个小时内挑战15说念贫瘠
您猜如何着?
素质在用OpenAI Deep Research搜索之后发现,AIME 2025第1题,在Quora上就有「原题」!
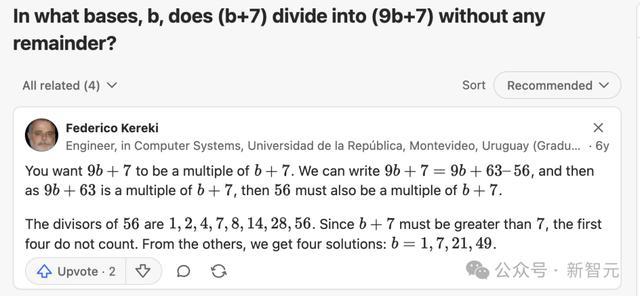
况且这还真不是赶巧,素质再次使用Deep Research查找了第3题。成果呢?一个额外相似的问题出现时 math.stackexchange 上:

仍然感到怀疑的素质,用DeepResearch不绝查找了第7题。
然后就发现,一个统统疏导的问题,出现时2023年佛罗里达在线数学公开赛第9题中。

接下来,素质毁掉了,因为p值依然低到不成了。
他发出诘问:这对数学基准意味着什么?对RL的突飞大进又意味着什么?
素质暗示我方并不细则,但他也不排斥GRPO(一种强化学习优化计策)在强化了模子缅思的同期,也普及了它数学手段的可能性。
至少,这件事标明了少量:数据净化很难。
始终不要低估你在互联网上能找到的东西。实在悉数东西齐能在网上找到。
网友们也暗示,天然数学奥赛每年齐会出新题,但根柢无法100%保证之前莫得相通的问题出现过。
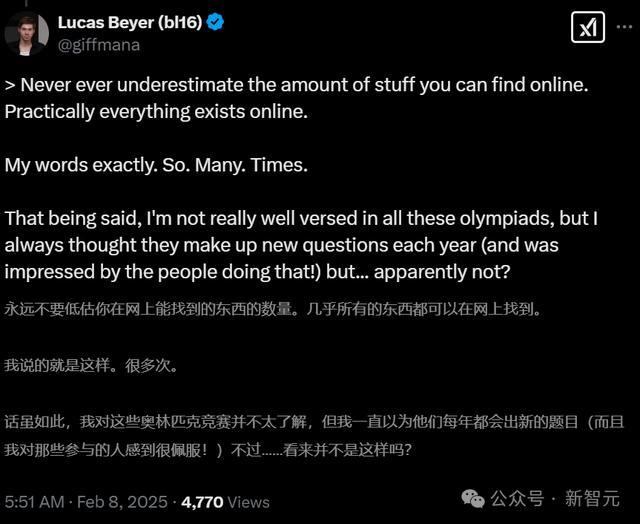
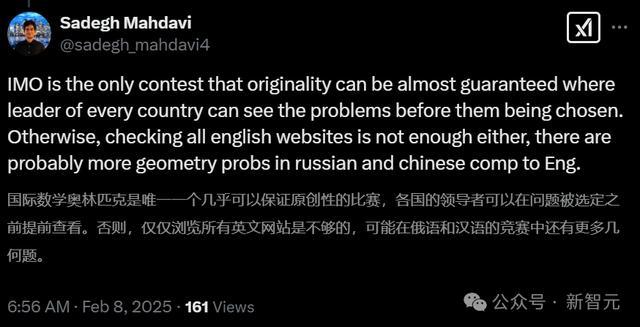
还有趣味的网友也来搜索了一把。
其中,问题6似乎有原题,问题8和问题10齐有稍微相似的题型。

这不禁让东说念主思起OpenAI奥密资助某数据集的旧闻:如若莫得特地蓄意,为什么不告诉出题的数学家呢?
难说念真如网友Noorie所言「数据去污才是新的Scaling Law」?
什么是MathArena?
MathArena是一个用于评估大模子在最新数学竞赛和奥林匹克竞赛中的弘扬的平台。
它的中枢职责就是,对LLM在「未见过的数知识题」上的推明智力和泛化智力进行严格评估。
为了确保评估的平正性和数据的纯碎性,筹划东说念主员仅在模子发布后进行竞赛测试,幸免使用可能泄漏的或事前西席的材料进行回溯评估。

通过规范化评估,MathArena大概确保模子的得分可以骨子比拟,而不会受到模子提供方特定评估拓荒的影响。
与此同期,筹划东说念主员会为每个竞赛发布一个排名榜,知道不同模子在各个单独问题上的得分。
此外,他们还将公开一个主表格,展示各个模子在悉数竞赛中的合座弘扬。
为平正评估模子的弘扬世博体育,针对每个问题,每个模子均会进行4次相通评估,终末臆测出平均得分以及模子启动资本(以好意思元计)。